核函数的定义并不困难,根据泛函的有关理论,只要一种函数 K ( x i , x j ) 满足Mercer条件,它就对应某一变换空间的内积.对于判断哪些函数是核函数到目前为止也取得了重要的突破,得到Mercer定理和以下常用的核函数类型: (1)线性核函数 (2)多项式核 (3)径向基核(RBF) Gauss径向基函数则是局部性强的核函数,其外推能力随着参数 σ 的增大而减弱。多项式形式的核函数具有良好的全局性质。局部性较差。 (4)小波核 (5)样条核 (6)Sigmoid核函数 采用Sigmoid函数作为核函数时,支持向量机实现的就是一种多层感知器神经网络,应用SVM方法,隐含层节点数目(它确定神经网络的结构)、隐含层节点对输入节点的权值都是在设计(训练)的过程中自动确定的。而且支持向量机的理论基础决定了它最终求得的是全局最优值而不是局部最小值,也保证了它对于未知样本的良好泛化能力而不会出现过学习现象。

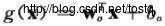

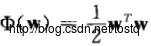




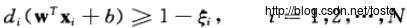
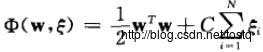
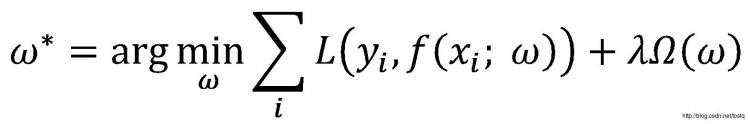

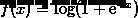 称为log loss;
称为log loss; 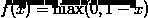 称为hinge loss。
称为hinge loss。 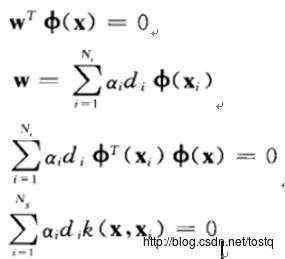







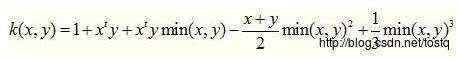

![Python3爬虫入门:pyspider的基本使用[python爬虫入门]](https://img1.php1.cn/3cdc5/324f/339/9d0ec9721f26646a.jpeg)







 京公网安备 11010802041100号
京公网安备 11010802041100号